
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- sql 데이터형 변환
- 동일성과 동등성
- 스프링뼈대
- GithubActions
- 자바 최소공배수
- 자바 유클리드
- islowercase()
- Github Actions
- string과 stringbuilder
- ineer join
- StringBuilder
- 유클리드호제법
- 래퍼타입
- git 컨벤션
- 최소공배수
- 스프링환경설정
- while과 two-pointer
- isuppercase()
- cicd
- 스프링
- string
- Git사용법
- 베주계수
- toLowerCase()
- 자바 스트링
- 프로그래머스 레벨1
- stringbuilder의 reverse()
- 최대공약수
- addDoc
- 모던자바
- Today
- Total
주노 님의 블로그
20241004 본캠프 56일차 TIL 본문
본캠프 56일차 내용 간단요약
- 09:00 ~ 10:00 : 코드카타
- 10:00 ~ 10:20 : 커리어 코칭
- 10:20 ~ 12:00 : 개인과제 구현
- 12:00 ~ 13:00 : 점심시간
- 13:00 ~ 14:00 : 면접준비
- 14:00 ~ 16:00 : 개인과제 구현
- 16:00 ~ 18:00 : 스프링 시큐리티 강의
- 18:00 ~ 19:00 : 저녁시간
- 19:00 ~ 21:00 : 개인과제 구현
커리어 코칭
코치님 : 접때 준비한 도메인 선정은 해왔나?
나 : 도메인선정보단 채용공고를 자주 보았다
코치님 : 궁금한점 있나?
나 : 채용공고에 중간중간 내가 배우지 못한 기술스택이 있다. 예를들면 spring mysql등등 하면서 중간에 go 이런게 섞여있다 이런곳도 지원해보는게 좋은가?
코치님 : 채용공고에서 자격요건과 우대사항이 있다, 대개 세분화해놓지않고 이런사람 저런사람을 뽑기위해 많이 적어놓는편이다,
코치님 : 공고에 서류에 자기소개서가 많은가? 포폴이 많은가?
나 : 아마 포폴이 많은것 같았다. 3:7정도..
코치님 : 현재 수준이나, 준비를 보아 미리 포폴을 작성해보는것도 좋을것같다.
개인과제 구현(level 10, 11, 13)
level 8
level10
query dsl을 짜기전
@GetMapping("/todos/details")
public ResponseEntity<Page<TodoResponse>> getTodo(
@RequestParam(defaultValue = "1") int page,
@RequestParam(defaultValue = "10") int size,
@RequestParam(required = false) String title,
@RequestParam(required = false, defaultValue = "2000-01-01") String startCreateDate,
@RequestParam(required = false, defaultValue = "2100-01-01") String endCreateDate,
@RequestParam(required = false) String managerName
) {
return ResponseEntity.ok(todoService.getTodoDetails(page, size, title, startCreateDate, endCreateDate, managerName));
}
컨트롤러를
public Page<TodoResponse> getTodoDetails(int page, int size, String title, String startCreateDate, String endCreateDate, String managerName) {
startCreateDate += " 00:00:00";
endCreateDate += " 23:59:59";
Pageable pageable = PageRequest.of(page - 1, size);
LocalDateTime startLocalDate = LocalDateTime.parse(startCreateDate, DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
LocalDateTime endLocalDate = LocalDateTime.parse(endCreateDate, DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
Page<Todo> todos = todoRepository.findByDetails(pageable, title, startLocalDate, endLocalDate, managerName);
return todos.map(todo -> new TodoResponse(
todo.getId(),
todo.getTitle(),
todo.getContents(),
todo.getWeather(),
new UserResponse(todo.getUser().getId(), todo.getUser().getEmail()),
todo.getCreatedAt(),
todo.getModifiedAt()
));
}
서비스를 만들어봤다
쿼리를 보니 한번에는 만들기 글렀다 싶어서 mysql로 먼저 작성을 하였다
select t.id, t.title,
count(distinct m.id) "매니저 수", count(distinct c.id) "댓글 수"
from todos t
left join managers m on t.id = m.todo_id
left join users u on u.id = m.todo_id
left join comments c on t.id = c.todo_id
where t.title like "%tl%" and t.created_at between '2024-10-01' and '2024-10-04' and u.nickname like "%ni%"
group by t.id
order by t.created_at desc;
위를 이제 query dsl로 작성해보자
@Override
public Page<TodoDetailResponse> findByDetails(Pageable pageable, String title, LocalDateTime startLocalDate,
LocalDateTime endLocalDate, String managerName) {
List<TodoDetailResponse> todos = jpaQueryFactory
.select(Projections.constructor(TodoDetailResponse.class, todo.id,todo.title, manager.id.countDistinct(), comment.id.countDistinct()))
.from(todo)
.leftJoin(todo.managers, manager)
.leftJoin(todo.comments, comment)
.leftJoin(manager.user, user)
.where(
todo.title.contains(title),
todo.createdAt.between(startLocalDate, endLocalDate),
user.nickname.contains(managerName)
)
.groupBy(todo.id)
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
long total = jpaQueryFactory
.select(todo.count())
.from(todo)
.fetchOne();
return new PageImpl<>(todos, pageable, total);
}
오류 > 제거 > 오류 > 제거 > 오류 > 제거...를 한뒤 결과가 나왔다
level11
매니저 등록시 로그를 달아야한다
매니저 등록 및 등록실패시에도 로그를 달아줘야한다고 한다
로깅 관련 클래스를 만들어주고
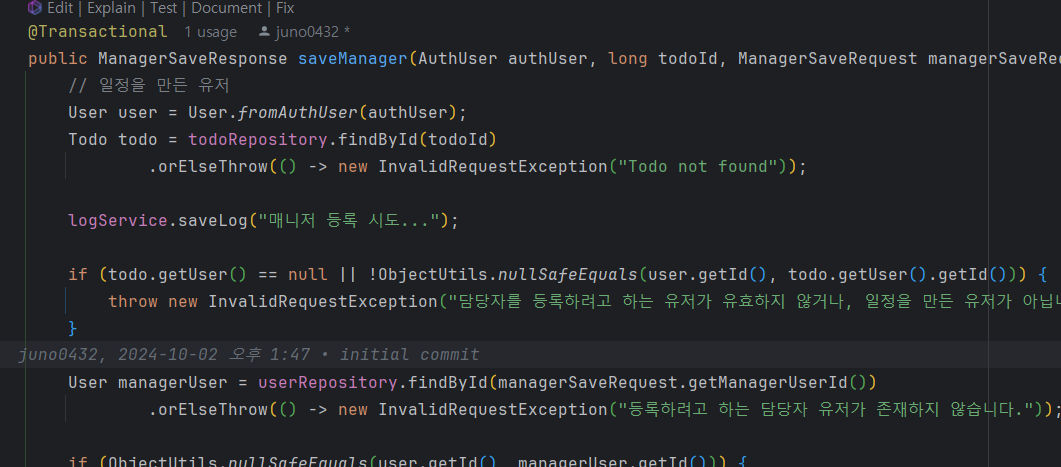
매니저 등록시 logservice에서 savelog 메서드를 호출해준다
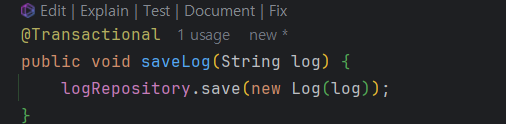
다만 logservice에서 트랜잭션 전략을 다르게 걸어줘야 saveManager이 실패해도 등록이 가능한데
이럴때 사용하는게 propagation이다
하나의 메서드 실행시 트랜잭션은 connection을 가져오고, 닫는즉시 connection이 풀리면서 commit() 호출하게 되는데
만약 트랜잭션 도중 예외가 발생하면 rollback()가 호출이 된다.
manager save메서드 안에 logservice save가 있는 상태이다.
그럴경우 manager save메서드가 실패할경우 logservice.save는 한 트랜잭션 안이라 실패하게 된다.
트랜잭션 전파 속성 (Transaction Propagation)이 있는데
한 트랜잭션을 사용도중, 다른 트랜잭션을 사용할경우가 있는데, 이미 트랜잭션을 실행도중, 다른트랜잭션은 어떻게 시작할지를 결정한다
기본 @Transaction을 사용할때는 기본타입이 REQUIRED로
이미 진행중인 트랜잭션이 있으면 그 트랜잭션을 사용하고, 없으면 새 트랜잭션을 시작하는것이다
위 코드를 실행한다면, saveManager에서 트랜잭션이 이미 실행중이라, logServics에서는 기존 트랜잭션에 걸쳐진 상태라 rollback이되면 저장이 되지않는다
즉 위 요구사항(매니저 등록 실패시라도 로깅은 등록되어야한다)를 만족하기 위해서는 전파옵션을 다른 방법으로 사용해야하는데
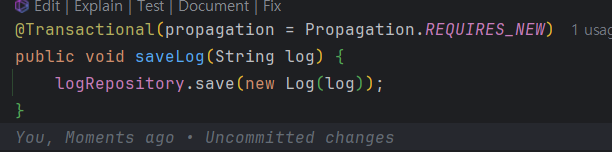
REQUIRES_NEW 옵션을 사용해야한다.
항상 새 트랜잭션을 시작하며, 진행중인 트랜잭션은 잠시 중단하는 전략이다
따라서 위 코드에서 saveManager이 실행되더라도, log메서드가 실행될때 saveManager이 중지되며, log메서드가 완료된 후 saveManager이 실행된다.
왜 사용할까? 현재 트랜잭션의 성공 여부와 상관없이, 로그나 감시 작업과같은 경우에 사용된다
그외 다른 전략을 확인해보자
SUPPORTS : 트랜잭션이 존재하면 이를 사용하고, 없으면 트랜잭션 없이 실행된다
>> 조회 작업등에서는 트랜잭션을 요구하지 않아도 될 경우
NOT_SUPPORTED : 트랜잭션이 있으면 이를 잠시 보류하고 트랜잭션 없이 실행해야할 경우
>> 조회 작업등에는 트랜잭션을 사용하면 성능에 부정적인 영향을 가질수 있는경우
MANDATORY : 반드시 현재 트랜잭션 내에서 실행되어야하며, 트랜잭션이 존재하지 않는 경우에 예외를 발생시킨다
>> 트랜잭션 내에서만 실행되어야 하는 중요한 작업이 있을때
NEVER : 트랜잭션 없이 실행해야하며, 트랜잭션있으면 예외를 처리한다
NETSTED : 트랜잭션이 존재하면 중첩 트랜잭션을 시작한다, 만약 트랜잭션이 없으면 새로운 트랜잭션을 시작한다
level 13
더미데이터 생성
더미데이터는 정렬되지않은 상태를 조건으로 하기 떄문에 대-상혁 faker를 사용해서 등록했다
더미데이터를 100만건 생성하는데 걸리는 시간 측정
각각 save 2만건
Time taken: 49239 ms
saveAll이용 2만건
Time taken: 24213 ms
배치사이즈를 이용한 saveAll사용
Time taken: 1076876 ms
약 20분가량이 걸렸다.
saveAll도 결국에는 for문을 돌기때문에 다른방법으로 조회를 해볼것을 다짐했다
(과제 끝나고, redis 끝나고, docker 끝나고....)
bulk insert를 이용하면 이보다 빠를 수 있다.
일단 조회를 하기위해 아래 내용을 더 공부했다.
QueryDsl사용
1. JPAQueryFactory를 사용하면 queryDsl을 사용하면 상속, 구현등을 제거해도된다
2. 동적쿼리는 BooleanExpression을 사용한다
booleanBuilder을 사용한다면 if문으로 가득찰수있다.
BooleanExpression을 사용한다면 메서드형식으로 작성한다면 가독성등이 올라간다
select를 사용할때
exist메서드 금지
>> sql exists는 특정 조건을 만족하는 row가 있다면, 쿼리가 종료되지만, count는 첫번째쿼리가 발견되더라도 성능이 느려진다. 만약 스캔대상이 앞에있다면 exist는 일찍끝나지만, count는 비슷하다.
queryDsl의 exist메서드는 count를 사용하기때문에 성능 issue가되는 count를 사용하게된다.
그럼 위 방식을 어떻게 구현하면 좋을까?
limit 1 (fetchFirst())로 제한을 건다.
>> 조회결과가 0이냐 1이냐가 아니라 null 인지 판단해야한다
cross join 회피
>> cross join의 경우에는 나올 수 있는 모든 경우의 수를 체크하기떄문에 웬만하면 피하는게좋다
묵시적 조인이 될수있는데
명시적 조인으로
entity보다는 dto우선
>> entity를 조회하면 불필요한 컬럼이 조회될수도 있다.
>> 실시간으로 entity를 변경한다면 entity조회를 사용해야겠지만 dto조회를 통한 개선을 할 수 있다.
조회컬럼 최소화방법은
dto를 사용하여 조회하고싶은 부분만 조회를 한다
일단 조회를 해보자
public UserResponse getUserName(String nickname) {
long startTime = System.currentTimeMillis();
User user = userRepository.findByNickname(nickname)
.orElseThrow(() -> new InvalidRequestException("User not found"));
long endTime = System.currentTimeMillis();
System.out.println("getUserName: " + (endTime - startTime) + "ms");
return new UserResponse(user.getId(), user.getEmail());
}
jpaRepository.findByNickName과
public UserResponse getUserNameByNickname(String nickname) {
User findUser = queryFactory
.selectFrom(user)
.where(user.nickname.eq(nickname))
.fetchFirst();
return new UserResponse(findUser.getId(), findUser.getEmail());
}
fetchFirst를 사용하여 보았다.
@Table(name = "users", indexes = @Index(name = "idx_nickname", columnList = "nickname"))
public class User extends Timestamped {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(unique = true)
private String email;
private String password;
@Enumerated(EnumType.STRING)
private UserRole userRole;
private String nickname;
public User(String email, String password,String nickname, UserRole userRole) {
this.email = email;
this.password = password;
this.nickname = nickname;
this.userRole = userRole;
}
또한 인덱스를 사용하여보았다.
jparepository 메서드사용
getUserName: 342690700ns
getUserName: 316390900ns
getUserName: 326660000ns
getUserName: 322528500ns
getUserName: 320589200ns
getUserName: 317597400ns
getUserName: 324842900ns
getUserName: 318948200ns
getUserName: 329027600ns
getUserName: 333686800ns
queryDsl사용
getUserName: 251973900ns
getUserName: 177014500ns
getUserName: 185738800ns
getUserName: 178206600ns
getUserName: 175147400ns
getUserName: 175800000ns
getUserName: 182981400ns
getUserName: 181083200ns
getUserName: 178170600ns
getUserName: 183978500ns
db인덱스 사용
jparepository 메서드사용
getUserName: 46605900ns
getUserName: 1350900ns
getUserName: 1441500ns
getUserName: 1401600ns
getUserName: 1475900ns
getUserName: 1450300ns
getUserName: 1640600ns
getUserName: 1534200ns
getUserName: 1433800ns
getUserName: 2488200ns
queryDsl사용
getUserName: 72094500ns
getUserName: 1540500ns
getUserName: 1158900ns
getUserName: 1141300ns
getUserName: 1098100ns
getUserName: 1333400ns
getUserName: 1419200ns
getUserName: 1222800ns
getUserName: 1183200ns
getUserName: 1379300ns
성능은 이렇게 측정되었으며
최초성능
JPARepository (기본): 342,690,700 ns (약 342.69 ms)
QueryDSL (기본): 251,973,900 ns (약 251.97 ms)
JPARepository + 인덱스 사용: 46,605,900 ns (약 46.61 ms)
QueryDSL + 인덱스 사용: 72,094,500 ns (약 72.09 ms)
평균성능
JPARepository : 325,296,220 ns (약 325ms)
QueryDSL : 187,009,490 ns (약 187ms)
QueryDSL + 인덱스 사용: 8,357,120 ns (약 8.36 ms)
JPARepository + 인덱스 사용: 6,082,290 ns (약 6.08 ms)
이제 redis를 사용해서 개선해보자.
레디스를 도커에 올리고 (왜 6379포트일까?)
@Cacheable(value = "userCache", key = "#nickname")
public UserResponse getUserName(String nickname) {
long startTime = System.nanoTime();
User user = userRepository.findByNickname(nickname)
.orElseThrow(() -> new InvalidRequestException("User not found"));
// UserResponse user = userRepository.getUserNameByNickname(nickname);
long endTime = System.nanoTime();
System.out.println("getUserName: " + (endTime - startTime) + "ns");
return new UserResponse(user.getId(), user.getEmail());
}
캐시를 사용했다
getUserName: 252,111,000 ns (약 252ms)
getUserName: 1,404,600 ns (약 1.40ms)
getUserName: 1,778,100 ns
getUserName: 1,506,500 ns
getUserName: 1,379,800 ns
getUserName: 1,375,500 ns
getUserName: 1,415,600 ns
getUserName: 1,643,900 ns
getUserName: 1,469,900 ns
getUserName: 1,727,100 ns
getUserName: 1,423,400 ns
처음 속도에서 저렇게 차이 나는 이유는
캐시에서 1차조회후 hit를 하지못해 db를 접근하기때문에 252ms 정도의 시간이 소요된다
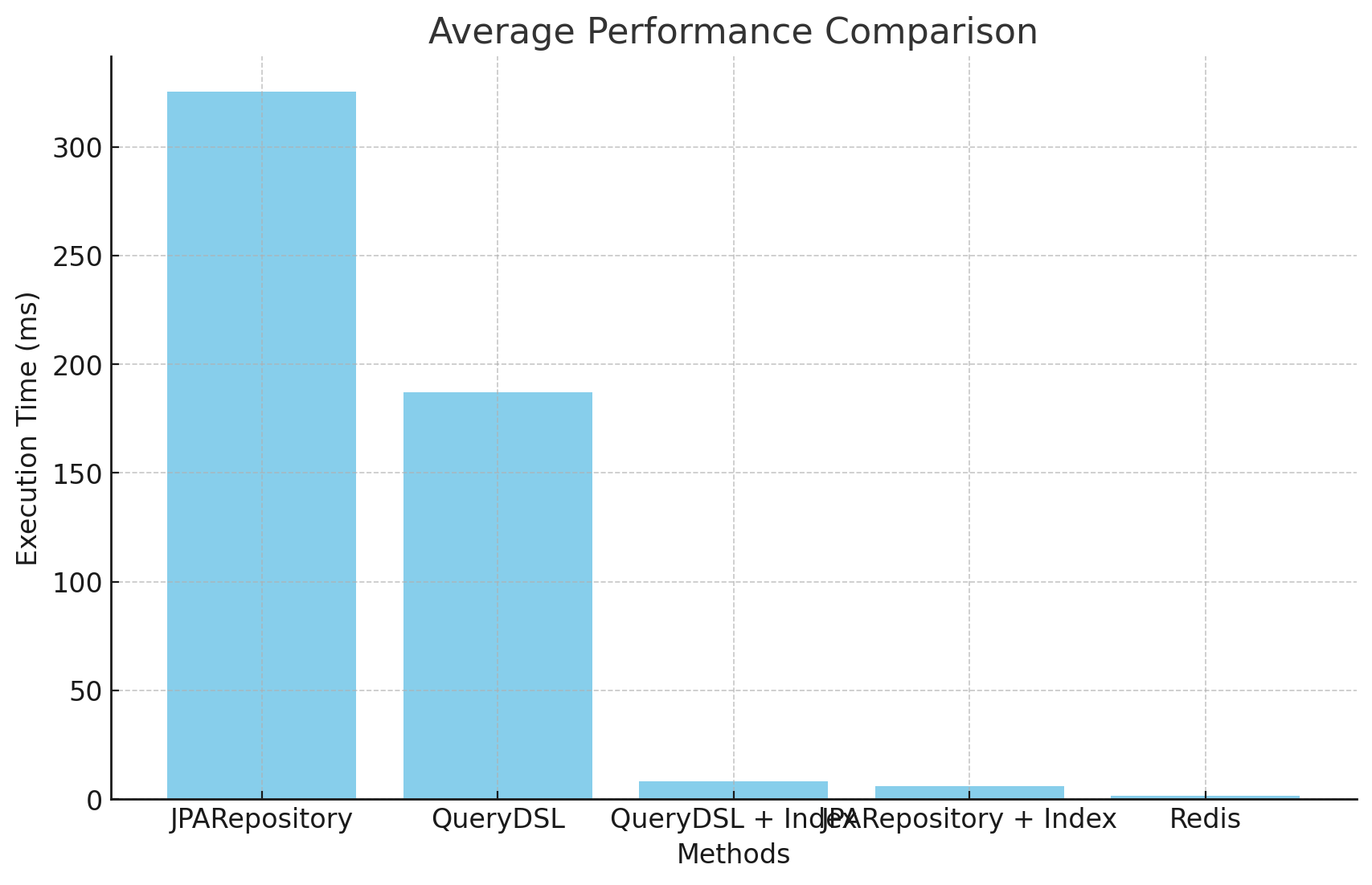
성능 개선이다.
jpa repository 기준 querydsl은 약 42.51% 성능 개선이 이루어졌으면
인덱싱을 추가하면 97.43%의 성능 개선이 이루어졌다
redis를 기준으로는 약 99.24%의 성능개선이 이루어진것을 볼 수 있다
이를 통해 인덱싱 또는 레디스의 사용이 조회의 성능에 큰 영향을 미친다는것을 알수있다.
참고자료
QUERY DSL
https://www.youtube.com/watch?v=zMAX7g6rO_Y
안녕하세요 교수님이 보라고 했는데, 안보고 이제본 저입니다..
REDIS 연결방법
[이슈] Redis 캐싱을 통해 조회 성능 개선하기
0. 들어가기 전현재 프로젝트에서 자주 호출하는 '동선 기간 조회' API의 조회 성능을 높이기 위해 캐싱을 도입하기로 했습니다. 위의 페이지에서 다음과 같이 '동선 기간 조회' API 호출이 발생합
ksh-coding.tistory.com
https://growth-coder.tistory.com/228
[Spring][Redis] 스프링 부트에서 redis 연동 및 RedisTemplate 사용법
이번 포스팅에서는 스프링 부트에서 redis와 연동하고 값을 저장해보려고 한다. 먼저 스프링 부트에 redis 관련된 의존성을 추가해준다. 만약 기존 진행 중인 프로젝트에 적용한다면 build.gradle에
growth-coder.tistory.com
'TIL' 카테고리의 다른 글
| 20241010 본캠프 59일차 TIL (1) | 2024.10.10 |
|---|---|
| 20241007 본캠프 57일차 TIL (0) | 2024.10.07 |
| 20241002 본캠프 55일차 TIL (0) | 2024.10.02 |
| 20241001 본캠프 54일차 TIL (1) | 2024.10.01 |
| 20240930 본캠프 53일차 TIL (0) | 2024.09.30 |


